机器学习简介
Q1 机器学习如何分类
按照任务类型可分为:
- 回归模型:例如预测明天的股价。
- 分类模型:将样本分为两类或者多类。
- 结构化学习模型:输出的不是向量而是其他结构。
按照学习理论可分为:
- 监督学习:学习的样本全部具有标签,训练网络得到一个最优模型。
- 无监督学习:训练的样本全部无标签,例如聚类样本。
- 半监督学习:训练样本部分有标签。
- 强化学习:智能体与环境进行交互获得奖励来进行训练的一种模式,环境不会判断是否正确,而是会不断的反馈信号来评价智能体的行为。
- 迁移学习:运用已经训练好的模型对新的样本进行学习,主要是解决问题中样本过少的问题。
Q2 什么是判别式和生成式模型
判别方法:由数据直接学习决策函数Y=f(X),或者由条件分布概率P(Y|X)作为预测模型为判别模型。
常见的判别模型有线性回归、boosting、SVM、决策树、感知机、线性判别分析(LDA)、逻辑斯蒂回归等算法。
生成方法:由数据学习x和y的联合概率密度分布函数P(Y,X),然后通过贝叶斯公式求出条件概率分布P(Y|X)作为预测的模型为生成模型。
常见的生成模型有朴素贝叶斯、隐马尔科夫模型、高斯混合模型、文档主题生成模型(LDA)等。
举例:
判断一个动物是大象还是猫,记住大象是长鼻子就可以判别出哪个是大象,将大象和猫画出来与动物进行对比,那个像就是那个。
性能度量
Q1 回归问题常用的性能度量指标有哪些
1)均方误差:是反映估计值与被估计量之间差异程度的一种度量。
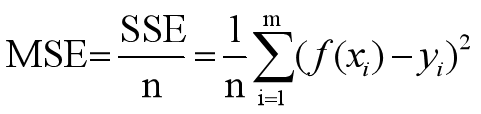
2)RMSE均方根误差:观测值与真值偏差的平方和与观测次数m比值的平方根,用来衡量观测值同真值之间的偏差。
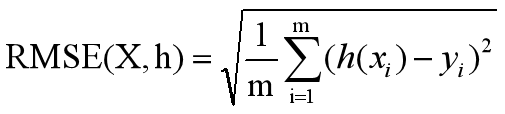
3)SSE和方误差
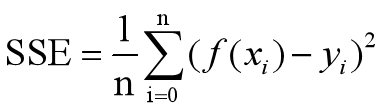
4)MAE:直接计算模型输出与真实值之间的平均绝对误差
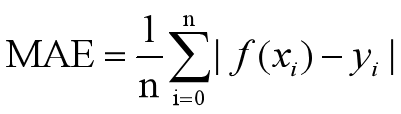
5)MAPE:不仅考虑预测值与真实值误差,还考虑了误差与真实值之间的比例。
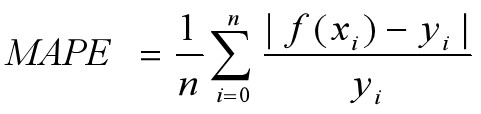
6)平均平方百分比误差
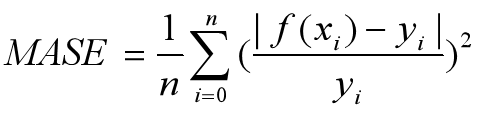
7)决定系数

Q2 分类问题常用的性能度量指标有哪些
常用的性能度量指标有:精确率、召回率、F1、TPR、FPR。
| 预测为真 | 预测为假 | |
|---|---|---|
| 真实为真 | TP(true positive) | FN(false negative) |
| 真实为假 | FP(false positive) | TN(true negative) |
精确率Precision=TP/(TP+FP)
召回率Recall=TP/(TP+FN)
真正例率即为正例被判断为正例的概率TPR=TP/(TP+FN)
假正例率即为反例被判断为正例的概率FPR=FP/(TN+FP)
精确率又称查准率,顾名思义适用于对准确率较高的应用,例如网页检索与推荐。召回率又称查全率,适用于检测信贷风险、逃犯信息等。精确率与召回率是一对矛盾的度量,所以需要找一个平衡点,往往使用F1是精确率与召回率的调和平均值:
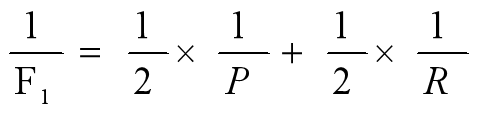
(1) 错误率和准确率
错误率:
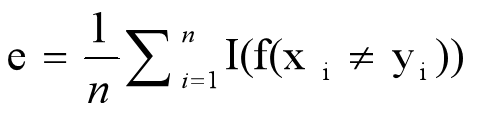
准确率:acc=1-e
(2)AUC与ROC曲线
对于0、1分类问题,一些分类器得到的结果并不是0或1,如神经网络得到的是0.5、0.6等,此时就需要一个阈值cutoff,那么小于阈值的归为0,大于的归为1,可以得到一个分类结果。
ROC曲线(Receiver Operational Characteristic Curve)是以False Positive Rate为横坐标,True Postive Rate为纵坐标绘制的曲线。
曲线的点表示了在敏感度和特殊性之间的平衡,例如越往左,也就是假阳性越小,则真阳性也越小。曲线下面的面积越大,则表示该方法越有利于区分两种类别。
AUC即为ROC曲线所覆盖的区域面积。




- 本文链接:https://www.tjzzz.com/posts/c0830c2e.html
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。