Q1 线性回归
在机器学习中线性回归模型是探讨变量y和多个变量x1,x2…xn之间的关系,用已有的训练为基础,总结问题本身的规律变化,并建立相应的回归模型来以预测未知样本的数据。
Q2 逻辑回归
逻辑回归是一个分类算法,它可以处理二元分类以及多元分类。
线性回归模型是求出输出特征向量Y和输入样本矩阵X之间的线性关系系数θ,使得其满足Y=Xθ,此时Y是连续的。
那离散的情况如何解决呢?
则可以将Y做一次函数转换:g(Y)。
如果令g(Y)的值在某个实数区间的时候是类别1,在另一个实数区间的时候是类别2.以此推类,模型就可以分类了。
这个函数g在逻辑回归中一般取为sigmoid函数,形式如下:
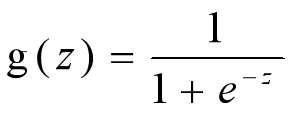
该函数有一个非常好的性质,即当z趋向于正无穷的时候,g(z)趋向于1,而当z趋向于负无穷的时候,g(z)趋向于0。这是非常好的一个分类模型性质,可以将(-∞,+∞)的结果映射到(0,1)上,并作为概率。另外他还有一个很好地导数性质:g`(z)=g(z)(1-g(z))
这个通过函数对g(z)求导很容易得到。
如果令g(z)中的z为:z=xθ,这样就得到了二元逻辑回归模型的一般形式:
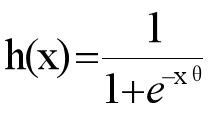
其中x为样本输入,h(x)为模型输出,可以理解为某一分类的概率大小。而θ为分类模型的要求出的模型参数。
h(x)值越小,而分类为0的概率越高,反之值越大分类为1的概率越高,如果靠近临界点,则分类准确率会下降。
逻辑回归可直接调用sklearn来实现:
sklearn.linear_model.LogisticRegression()其中重要参数如下。
- 正则化penalty
默认是L2的正则化,也可以选择L1正则化。如果在实际项目中发现过拟合情况严重或者由于模型特征过多,从而想让模型系数稀疏化可以选择L1正则化。
- 优化算法solver
- liblinear:即坐标轴下降法
- lbfgs:拟牛顿法的一种
- newton-cg:牛顿法的一种
- sag:随机平均梯度下降,该算法每次仅使用了部分样本计算梯度迭代,适合样本数据量很大的情况,收敛速度优于SGD和其他三种算法。
需要注意的是,正则化和优化相关联,如果选择L1正则化,则只能选择liblinear。这是由于L1正则化的损失函数不是连续可导的,而另外三种要求损失函数一阶可导或者二阶可导。
- 分类方式multi_class
multi_cclass参数即分类方式的选择,可以选择one-vs-rest(OvR)和many-vs-many(multinomial),需要注意的是liblinear无法使用multinomial这种分类方式。
OvR(One Vs Rest)是使用二分类算法来解决多分类问题的一种策略。从字面意思可以看出它的核心思想就是一对剩余。一对剩余的意思是当要对n种类别的样本进行分类时,分别取一种样本作为一类,将剩余的所有类型的样本看做另一类,这样就形成了n个二分类问题。
- 类别权重class_weight
class_weight参数是指分类模型中各种类型的权重。如果在class_weight选择balanced,则会根据训练样本量来计算权重。某种类型样本量越多,则权重越低,反之。提高了权重可以解决样本不平衡问题,sample_weight也可以解决这类问题。
Q3 逻辑回归模型如何进行多分类
多元逻辑回归常见的有OvR和MvM两种,OvR指每次将一个类的样例,所有其他类的样例作为反例来训练N个分类器,在测试时若有一个分类器预测为正类,则对应的类别标记作为分类结果。
MvM指每次将若干个类作为正类,若干个其他类作为反类。
此处介绍一种比较简单的多分类算法:
假设N元分类模型,把所有第N类的样本作为正例,除了第N类样本以外的所有样本都作为负例,然后在上面进行二元逻辑回归,得到第N类分类模型。其他类的分类模型获得一次忒累。
可以使用多项式逻辑回归模型计算最后得出概率值:
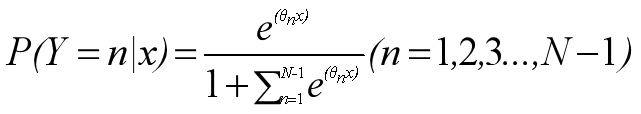
Q4 逻辑回归分类和线性回归的异同点是什么
逻辑回归模型本质上是一个线性回归模型,是以线性回归为理论支持的。但线性回归模型由于没有sigmoid函数的非线性模式,所以不易处理0/1分类问题。
另外一方面经典线性模型的优化目标函数时最小二乘,而逻辑回归则是似然函数,另外线性回归的预测值是整个实数域范围内,而逻辑回归的预测值是[0,1]。




- 本文链接:https://www.tjzzz.com/posts/557b3508.html
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。