想要获取完整代码,请访问面包多进行支持哦,仅需一口奶茶的钱!
一、实验目的
实现基于蒙特卡洛法的21点问题的最优解,了解强化学习的基本原理,理解蒙特卡洛法并编写相应的代码。
二、实验内容
赌场上流行的21点纸牌游戏的目的是获得其数值之和尽可能大而不超过21的牌。所有的人形牌面都算作10,而A可以算作1或11。我们的实验仅考虑每个玩家独立与庄家竞争的版本。游戏开始时,庄家和玩家都有两张牌。庄家的一张牌面朝上,另一张牌面朝下。如果玩家有21张牌(一张A和一张10牌),则称为自然牌。他就赢了,除非庄家也有自然牌,在这种情况下,游戏是平局。如果玩家没有自然牌,那么他可以要求额外的牌,单张发牌(hits),直到他停止(sticks)或超过21(goes bust)。如果他破产,那么他输了,如果他坚持,那么就轮到庄家的回合。庄家hits或sticks或者goes bust;在牌数字和为17或更多的时候,庄家就停止发牌。赢、输、或平局由谁的最终和值更接近21决定。
三、实验过程
本次实验需要导入如下包:
import gym
import numpy as np
from collections import defaultdict
import matplotlib
import matplotlib.pyplot as plt运用gym自带的21点游戏进行接下来的编程:
env = gym.make('Blackjack-v0')
observation = env.reset()
print(env.action_space, env.observation_space, sep='\n')这段代码返回了玩家的当前点数之和 ∈{0,1,…,31} ,庄家朝上的牌点数之和 ∈{1,…,10} ,及玩家是否有能使用的ace(no =0 、yes =1 ),和智能体可以执行两个潜在动作:STICK = 0,HIT = 1。
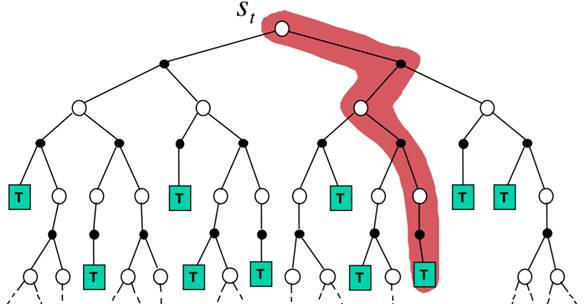
本次实验采用On-policy first-visit MC control,On-policy方法在一定程度上解决了exploring starts这个假设,让策略既greedy又exploratory,最后得到的策略也一定程度上达到最优。如下图所示:

我们定义一个嵌套函数:
def make_epsilon_greedy_policy(Q_table, nA, epsilon):
def generate_policy(observation):
prob_A = np.ones(nA) * epsilon / nA
optimal_a = np.argmax(Q_table[observation])
prob_A[optimal_a] += (1.0 - epsilon)
return prob_A
return generate_policyMC算法是逐幕进行的,所以我们要根据策略来生成一幕数据。
这里要注意:generate_policy是一个函数即make_epsilon_greedy_policy的返回值。generate_policy的返回值是 π \piπ 。这里循环了1000次只是为了确保能获得完整的一幕。
接下来是MC控制的主体部分,我们要循环足够多的次数使得价值函数收敛,每次循环都首先根据策略生成一幕样本序列,然后遍历每个“状态—价值”二元组,并用所有首次访问的回报的平均值作为估计.
这里要注意:Return和Count是字典,每个“状态—价值”二元组是一个key,该二元组每一幕的回报是它的value,随着越来越多的迭代,根据大数定律,它的平均值会收敛到它的期望值。并且在下一轮迭代生成另外一幕样本序列的时候,generate_policy函数会根据Q_table更新。
def MC_control(env, iteration_times=500000, epsilon=0.1, discount_factor=1.0):
Return, Count, Q_table = defaultdict(float), defaultdict(float), defaultdict(lambda: np.zeros(env.action_space.n))
policy = make_epsilon_greedy_policy(Q_table, env.action_space.n, epsilon)
for i in range(iteration_times):
if i % 1000 == 0:
print(str(i) + "次")
trajectory = generate_one_episode(env, policy)
s_a_pairs = set([(x[0], x[1]) for x in trajectory])
for state, action in s_a_pairs:
s_a = (state, action)
first_visit_id = next(i for i, x in enumerate(trajectory) if x[0] == state and x[1] == action)
G = sum([x[2] * (discount_factor ** i) for i, x in enumerate(trajectory[first_visit_id:])])
Return[s_a] += G
Count[s_a] += 1.
Q_table[state][action] = Return[s_a] / Count[s_a]
return policy, Q_table接下来是将价值函数可视化:
def plot_value_function(Q_table):
x = np.arange(12, 21)
y = np.arange(1, 10)
X, Y = np.meshgrid(x, y)
Z_noace = np.apply_along_axis(lambda x: Q_table[(x[0], x[1], False)], 2, np.dstack([X, Y]))
Z_ace = np.apply_along_axis(lambda x: Q_table[(x[0], x[1], True)], 2, np.dstack([X, Y]))
def plot_surface(X, Y, Z, title):
代码过长略实验结束。想要获取完整代码,请访问面包多进行购买
四、实验结果
运行如上代码,在代码文件RL中,输出图所示:
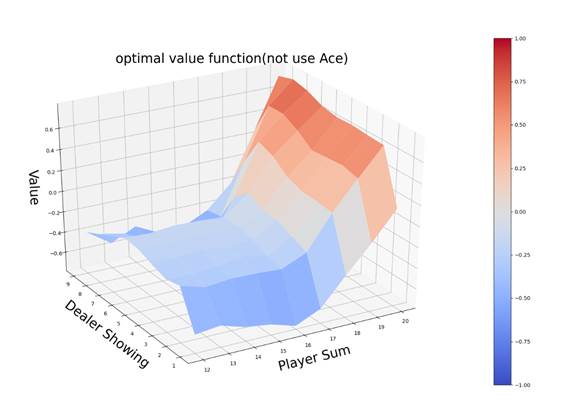
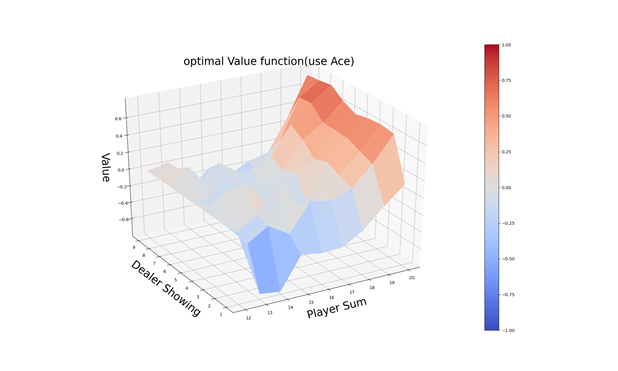




- 本文链接:https://www.tjzzz.com/posts/4c5e754e.html
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。